
Hakowanie IAT (user-space), czyli trochę wstępu z budownictwa
Art będzie miał swój ciąg (jeden lub więcej) dalszy, gdyż całość zostanie potraktowana raczej jako forma luźnej notatki. Zapiski te prawdopodobnie posłużą mi przy pisaniu pracy dyplomowej pod warunkiem, że znajdzie się jakiś ktoś, kto zechce mnie pod tym kątem przetestować. Będzie to zatem skromna część całości, która traktować będzie o całym kernelowym undergroundzie (czyli znacznie poniżej API).
Zanim postaramy się przejąć po części władzę nad plikiem wykonywalnym - musimy poznać ten obiekt, wiedzieć o nim trochę ( jego przyzwyczajenia, relacje a w szczególności jego cyfrową dietę ). W tym arcie postaram się doprowdzić Nas do zrozumienia zagadnień wciskania się w przestrzeń wirtualną innego procesu w systemie Windows. Miejmy nadzieję, że po jego przeczytaniu pojęcią takie jak :
- PE (VA,RVA, moduł wykonywalny a plik na dysku, obiekt-mapowanie, .. );
- IAT, ILT ? Import Address Table, Import Lookup Table ( FirstThunk,OriginalFirstThunk, .. );
- DLL, biblioteki importu - __declspec( dllexport ), *.lib( *.a);
- Żonglerka rzutowaniem struktur - czyli nakładamy foremki na obszary pamięci, zakrywamy i odkrywamy co się da i przyda;
- SetWindowsHookEx() - haki, haki, hooks;CreateRemoteThread() - knock knock! Please come in, welcome();
Portable Executable aka PE to międzyplatformowy format pliku wykonywalnego ( plikiem wykonywalnym nazywamy tu zarówno pliku typu: program.exe oraz biblioteka.dll ). Zajrzyjmy na chwilę na wikipedię -
Portable Executable (PE) - (..) Format PE jest po prostu strukturą danych, która zawiera informacje potrzebne systemowi do zarządzania kodem wykonywalnym. Należą do tego: referencje do bibliotek DLL, tablice importowanych i eksportowanych funkcji API, dane do zarządzania zasobami, informacje o wątkach.
W systemach z rodziny NT format PE jest używany m.in. przez pliki *.exe, *.dll, *.obj, *.sys (najczęściej plik sterownika). (..) PE jest zmodyfikowaną wersją Uniksowego formatu COFF stąd też jego alternatywna nazwa - PE/COFF. W systemach Windows NT PE obecnie może zawierać zarówno instrukcje z zestawu IA-32 jak i IA-64 oraz x86-64 (AMD64 i EM64T) (..) .
Podobają Nam się szczególnie hasła 'struktura danych' oraz 'tablice importowanych i eksportowanych funkcji API' - reszta interesuje nas teraz mniej nie więcej.
Jak wygląda plik PE?
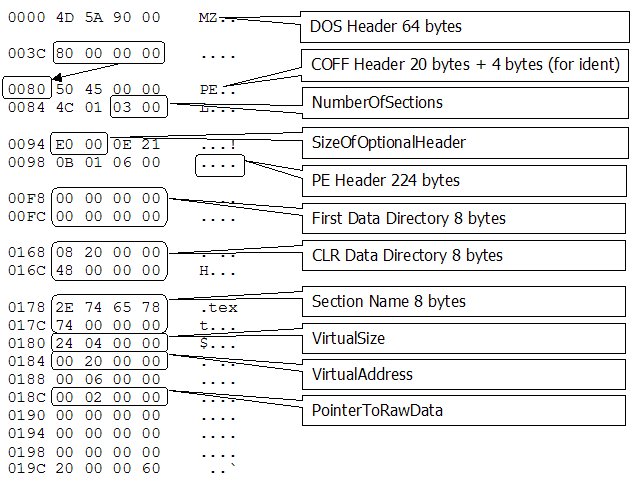
Ten blackBox ma to do siebie, że do pewnego momentu jest ładnie ułożony a po tablicy sekcji to już zależy i trzeba kombinować.. (powoli!) Wszystkie informacje na temat składowych struktur pliku znajdziemy w pliku winnt.h
Budowa - Part I:
NAGŁOWEK DOS - to początek pliku, pierwszy bajt pliku w pamięci to pierwszy bajt struktury opisującej tą część pliku wykonywalnego! Jak ona wygląda:
Dokładny opis wszystkich pól ( jeśli jesteś zainteresowany / ana ) możesz znaleźć w specyfikacji formatu np. pod tym adresem :
www.osdever.net/documents/PECOFF.pdf lub ( szczególnie polecam (eng.) )
http://www.codebreakers-journal.com/downloads/cbj/2006/CBM_1_2_2006_Goppit_PE_Format_Reverse_Engineer_View.pdf
http://msdn.microsoft.com/en-us/magazine/bb985992.aspx
http://msdn.microsoft.com/en-us/magazine/cc301808.aspx
Z tej struktury interesują Nas pierwsze i ostatnie pole. Why? Identyfikator MZ powiadamia nas, że w ogole mamy do czynienia z plikiem wykonywalnym.

Będzie nam on potrzebny, żeby sprawdzić czy plik z którym chcemy coś zrobić w ogole się do tego nadaje! Zagadka dla sprawdzenia ogólnej orientacji - gdybym zapytał się Ciebie teraz, w którym momencie na tym obrazku kończy ( a może nie kończy ) się nagłówek DOS'a ?
Podpowiedź: Czym jest 4D? Czymś podobnym do FF, 4D to to samo co 0x4D a FF to inaczej 0xFF. FF to inaczej również 1111 1111 czyli 8 jedynek postawionych na baczność, czyli jest to jeden bajt. Czyli 4D również oznacza tutaj jeden bajt, czyli XX XX XX .. oznacza tutaj 4 bajty. W takim razie ile takich bajtów składa się na strukturę IMAGE_DOS_HEADER ? WORD to 2 bajty ( XX XX ), LONG natomiast 4 bajty ( XX XX XX XX ), czyli już wiadomo jak to interpretować i policzyc.
Ostatnie pole ( e_lfanew ) informuje nas o offsecie nagłowka PE - czyli tego co jest po nagłowku dos'a oraz dos stub'ie czyli:

Mamy nadzieje, że wiemy co to offset - jakby któryś z nas nie wiedział to niech zapamięta, że to pozycja względem innej pozycji. Np. nagłowek PE znajduje się o 'plus offset' względem adresu pierwszego bajtu pliku. Czyli jeśli mamy bieg na 100m to META znajduje się o offset równy 100m względem początku czyli START'u. Zawodnicy na różnych etapach biegu osiągają różne wartości offsetu ( czyli przesunięcia ) względem START'u.
No i wiemy już przez to trochę więcej o haśle pod tytułem RVA - Relative Virtual Address to wartość offsetu czyli przesunięcia względem początku pliku w pamięci.
A czym będzie VA? Virtual Address będzie adresem początku pliku wraz z przesunięciem czyli z RVA.
VA = baseAddress + RVA gdzie baseAddress jest adresem początku pliku w pamięci.

Obrazkowo wygląda to w ten spoób. To zrzut z programu PEView i widać tutaj relatywny adres ( czyli offset ) ( IAT ( IMPORT (ADDRESS) Table ) względem początku pliku - wynosi on 5000.

Przesuneliśmy się w programie na widok sekcji .idata ( czyli na importy ) i widać tutaj, że zaczyna się ona w pamięci od adresu (VA)405000 czyli baseAddress(400000) + RVA(5000). Teraz już wiesz czym jest VA oraz RVA. Po nagłowku i stubie przyszedł czas na PE Header. IMAGE_NT_HEADER - składa się on z Sygnatury, FileHeader oraz OptionalHeader:
Jak dostać się np do DWORD Signature - Signature jest identyfikatorem nagłówka PE, może przybierać różne wartości w zależności od typu pliku, np.: IMAGE_NT_SIGNATURE equ 4550h - aka 'PE'
- załóżmy że pMapa zawiera baseAddress pliku wykonywalnego, zatem:
..i w ten sposób mamy już wypełnioną strukturę zmiennej pDosHeader, mamy więc i e_magic oraz min e_lfanew!
Offset nagłówka PE można odczytać na 2 sposoby - można skorzystać z funkcji ImageNtHeaders z biblioteki dbghelp.dll ( pokazane wyżej ) lub wykonać dodawanie:
Why? Bo jak wiemy e_lfanew zawiera RVA 'PE' czyli offset względem pMapa. Wypełnijmy teraz strukturę IMAGE_FILE_HEADER:
Oraz szczególnie ważną kolejną strukturę IMAGE_OPTIONAL_HEADER:
Z tego co posiadamy teraz w zmiennej pOptional interesuje Nas min:
- WORD magic; -- kolejny identyfikator, który dla formalności wypada sprawdzić.
- DWORD ImageBase; -- to jest adres pod który ładowany jest w pamięci operacyjnej nasz plik wykonywalny, w przypadku execow jest to zazwyczaj: 0x00400000 (baseAddress)
- IMAGE_DATA_DIRECTORY DataDirectory[16]; -- tutaj odczytamy sobie RVA do Import Table, jak pamiętamy z przykładu wyżej wynosił on 5000.
- DataDirectory jest tablicą składającą się z 16 elementów, takich właśnie:
DWORD VirtualAddress zawiera owe 5000
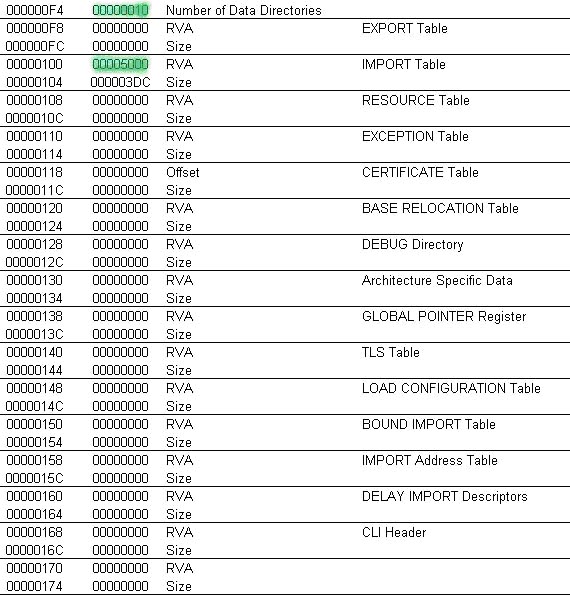
Jak widać pod adresem w pliku na dysku (widok - pFile w programie PEView) 4f znajduje się wartość szesnastkowa 0x10 czyli decymalnie - 16: Number of Data Directories. Możemy już teraz znając adres sekcji .idata w pliku wykonywalnym, zastanowić się jakie struktury będą nam potrzebne do opisu tego obszaru pamięci.
W wielkich skrótach - IMAGE_IMPORT_DESCRIPTOR opisuje biblioteke DLL, z tej struktury dowiemy się min o nazwie pliku biblioteki dll z której program importuje funkcje.
Z tej struktury też dowiemy się kolejnych dwóch rzeczy - składowa OriginalFirstThunk zawiera RVA tablicy ILT ( Import Lookup Table ) ; składowa FirstThunk zawiera natomiast RVA do tablicy IAT ( Import Address Table). Teraz tak, wyobraź sobie ten obszar pamięci na który wskazuje OriginalFirstThunk plus baseAddress i pomyśl że od jego początku układamy formy ze struktur IMAGE_THUNK_DATA :
Jedną foremka za drugą w pamięci i tak aż do momentu napotkania na ostatnią importowaną funkcję. Jak widać mamy tutaj do czynienia po prostu z unią. Z tej unii interesują nas szczególnie dwa pola - Function - zawiera wskażnik na strukturę IMAGE_IMPORT_BY_NAME :
Mamy tutaj dwie składowe Hint - stanowi indeks funkcji w tabeli exportu biblioteki. Name - jak się można domyślić zawiera nazwę importowanej funkcji. Wróćmy do IMAGE_THUNK_DATA32 - mamy tam jeszcze pole Ordinal. O co chodzi, trzeba wiedzieć, że funkcja może być zaimporotwana do pliku wykonywalnego przez wartość aka indeks aka Hint aka Ordinal !!! O co w ogole chodzi z tym polem Ordinal - otóż wykorzystując to pole możemy prostym iloczynem logicznym bitów sprawdzić czy dana funkcja została zaimportowana przez wartość czy nie:
jeśli w wyniku tej operacji wyjdzie 0 czyli bit IMAGE_ORDINAL_FLAG nie jest ustawiony to wykonana zostanie jakaś operacja bo mamy ! z przodu a !0 da 1 czyli wykonana zostanie instrukcja po if. Jeżeli funkcja zaimportowana jest przez indeks to znaczy, że nie jest zaimportowana przez nazwę. Kolejną rzeczą jaką trzeba wiedzieć jest to, że właściwie tablice struktur IMAGE_THUNK_DATA - nie pomyliłem się w nazwie, bo:
- na które wskazuje OriginalFirstThunk oraz tablice struktur IMAGE_THUNK_DATA na które wskazuje FirstThunk są takie same - pierwsza z nich jest nieruszana i na stałe wklepana w plik wykonywalny. Druga natomiast wypełniana jest przez loader windows adresami funkcji importowanych z bibliotek DLL.
Zwrócmy uwagę, że Import Name Table oraz Import Address Table są identyczne w PEView ? do czasu. Loader nadpisze FirstThunk adresami importowanych funkcji. Każda foremka IMAGE_THUNK_DATA będzie stanowić teraz DWORD?owy adres funkcji z biblioteki, popatrz że cała struktura która w rzeczywistości jest unią jest pewnym obszarem w pamięci o wielkości właśnie DWORD czyli wielkości równej adresowi w pamięci bo w przypadku procesorów 32 bitowych adres składa się z wielkości DWORD.
Nie zobaczymy tych adresów w programie PEView gdyż PEView nie ładuje pliku programu tak jak robi to loader, czyli np. nie umieszcza baseAddress pod 0x00400000 adresem w pamięci. Jeśli nie jest to loader zatem nie wypełni też adresami struktur IMAGE_THUNK_DATA z tablicy FirstThunk aka IAT. Jak się zatem domyślasz - operacji ewentualnego przejęcia władzy nad execiem trzeba będzie dokonać na żywym organizmie rezydującym oryginalnie na swoich zasadach w pamięci.
W swoim opisie doszliśmy już do tablicy IAT zatem nie będziemy rozdrabniać się tutaj bardziej. Zasada jest prosta - jeśli mapujesz plik i chcesz wyciągnać jakieś info z jego struktury to :
a) zobacz jaka struktura opisuje dane pole
b) zobacz jakie pola z innych struktur doprowadzą Cię do tej struktury
c) w przypadku mapowania i adresów RVA należy też pamiętać o korektach, popatrz o co chodzi:
Czyli jeśli zdasz się wyłącznie na RVA czyli np zechcesz odczytać jakąś informację z pod adresu baseAddress + RVA to bardzo prawdopodobne że nie trafisz na to co chciałeś. Musisz tutaj skorygować adres. PointerToRawData wynosi 1400 - oznacza to odległość od początku pliku zatem jeśli spojrzymy na przesunięcie sekcji .idata w PEView to mamy:

Jak widać sekcja importu znajduje się dokładnie baseAddress + PointerToRawData czyli

W przypadku parsowania programu załadowanego przez loader do pamięci nie należy się tym przejmować, tam korekty przy parsowaniu nie bedą obowiązywać. Tutaj nie mamy do czynienia z formą programu jaki rezyduje w pamięci podczas swojego wykonywania. Mamy tutaj do czynienia z formą pliku jaka rezyduje na dysku. A w pliku na dysku sekcja importu leży dokładnie baseAddress + PointerToRawData. W pamięci programu natomiast będzie to baseAddress + RVA i tyle.
Opis budowy pliku PE nie jest naszym celem więc więcej informacji i szczegółów już tutaj raczej nie przeczytamy. Mam nadzieję że hasło IAT nabrało dla nas już nieco bardziej kanciastych rys.
Musimy nauczyć się parsować, czyli przechodzić po tym pliku i wyciągać z niego różne ciekawe informacje. To ważne ćwiczenie i musimy przez to przejść a raczej przez PE. Od razu uwaga, jeśli nauczymy się skakać po strukturze PE łatwiej nam będzie skakać bo bardziej krytycznych strukturach systemowych - ale o tym później.
Jak się do tego zabrać? Na początek zajrzymy do dokumentacji MSDN i poszukamy czegoś o funkcjach CreateFile, CreateFileMapping, MapViewOfFile, UnmapViewOfFile - te funkcje pozwolą nam uzyskać 'uchwyt' (HANDLE) do pliku, odwzorować jego fizyczną postać na adresy wirtualnej przestrzeni naszego programu który będzie parsować exec'a a na koniec pracy zwolnić ten obszar pamięci.
Przedstawiam tutaj kod tego programu - nie skupiamy się na chwilę obecną jak dokładnie działa mapowanie pliku czy pozostałe funkcje. Interesuje Nas przede wszystkim to, że musimy mieć na uwadze że plik mapowany z dysku to nie moduł załadowany i wykonywany w pamięci we własnej przestrzeni adresowej. One różnia się ułozeniem w pamięci!
Kod dostępny jest tutaj
- jak np. zabrac się do odczytywania nagłowka DOS'a? - jest to ważne bo w podobny sposób będziemy odczytywac inne informacje z dalszych regionów pamięci na które zmapowany jest nasz exec.
Widzimy operacje rzutowania, czyli obrazkowo: biorę do reki forme ulepioną według budowy IMAGE_DOS_HEADER i kładę ją na początek zmapowanego pliku w pamięci. Ta forma pozwala mi na taki podział bajtów że możliwe sa one do odczytania. Czyli morze bitów zostało tak jakby podzielone na obszary np. po 16 bitów (WORD) lub np. po 32 bity (DWORD).
Może to przypominać mapkę geodezyjna z podziałem na działki - bez podziału widzę puste zielone pola, po podziale wiem już co do kogo należy, jaki działka ma numer itp. - ktoś nałożył dla mnie taką formę na mapkę i teraz jest ona dla mnie czytelna, widzę konkretne informacje a nie morze zieleni.
Dzięki rzutowaniu jestem w stanie np. zinterpretować e_magic bo na tę częśc morza bitów nałozyłem formę składająca się z 16 bitów czyli jednego WORDA. Interesują mnie tylko pierwsze 16 bitów - dzięki rzutowaniu mój program może odczytać te wartość.
Mógłbym to zrobić jeszcze inaczej, np. na początkowy obszar pamięci rzućić formę np.
Wskaznik = (DWORD)(PLIK_ZMAPOWANY) a na koniec zrobić taki myk:
Printf("%x",(WORD)(*wskaznik)) lub Printf("%x",(WORD)(*wskaznik).e_magic) i będzie dokładnie to samo jak zrobiłem to w kodzie wyżej.
Rzutowanie czyli nakładki / kładki / nalepki na pamięć to podstawa operacyjna!
Trochę o bibliotekach DLL
Absolutnie nie chce rozprawiać się nad filozofią i ogólną charakterystyką bibliotek DLL - chciałbym zwrócić uwagę na coś innego, na bardziej praktyczną stronę wykorzystywania tych plików. Każdy słyszał o 'dll-elkach' - ale nie każdy wie na jakiej zasadzie tak naprawdę one działają. Jeśli nurtują Cie kwestie związane z bibliotekami to w ciemno strzelam, że za chwilę owe kwestie zostaną poruszone i rozjaśnione.
Biblioteki mogą być ładowane do przestrzeni procesu na zasadzie :
- load time
- run time
Co oznacza load-time? Oznacza to tyle, że kompilowałeś swój program przy użyciu pliku biblioteki importowanej czyli pliku z rozszerzeniem *.lib lub np. *.a w przypadku tworzenia biblioteki w dev-cpp. Zasada przy tworzeniu jest taka: jeśli eksportujesz cokolwiek z biblioteki ( __declspec( dllexport ) ) to zawsze tworzony będzie plik biblioteki importowanej! Najpierw utworzyłeś nowy projekt, nastepnie w opcjach projektu dodałeś plik z rozszerzeniem lib lub a. Nastepnie skompilowales swój program a w opcjach linkera widzimy min Opcję -l, oznacza dodanie biblioteki do procesu tworzenia pliku wynikowego.
Teraz popatrzmy jak wygląda skompilowany i zlinkowany exec w programie PeView - otóż widzimy w sekcji .idata czyli w sekcji importu dokąd skierował nas nagłowek tej sekcji [IMAGE_SECTION_HEADER] nazwy standardowych bibliotek które Windows uzywa do tworzenia pliku ORAZ widzimy nasza biblioteke na stale wpisana już do tego pliku. Oprocz nazwy biblioteki widzimy nazwy które z niej importujemy.
No i co z tego? No a tyle, ze program aby działać teraz musi dołożyć jedynie plik nagłowka tej biblioteki ( wiadomo, że kazda nazwa musi być wcześniej znana! ) - dll.h i zapewnić dostępność tej biblioteki w ścieżkach ustawionych w projekcie bądź ścieżkach systemowych czyli np. w katalogu bieżącym. Dostepność biblioteki mam tu na myśli oczywiście DLL a nie owy *lib - ten pliczek służy do komunikacji z linkerem - przekazuje mu informacje jakie ten na sztywno koduje w execa. Jest to taki przewodnik po bibliotece i nazwach które importuje program główny.
Co więcej? Musisz pamiętać też, że biblioteka ładowana jest do przestrzeni procesu już w momencie jego uruchomienia! Zapamiętaj to, bo jest to cecha różniąca load time od run time.
W tym momencie możesz zadac jeszcze jedno pytanie - zaraz zaraz, a co w execu robią np. kernel32.dll msvcrt.dll i dlaczego ja nic nie wiem o tym jak one się tam znalazły?
Dobre pytanie, wylistujemy teraz z katalogu instalacyjnego dev'a pliki bibliotek importowanych. Widać tam zarówno plik kernel32.lib jak i msvcrt.lib ? skoro znajdują się one w pliku exec'a na takiej samej zasadzie jak nasza wcześniejsza biblioteka - oznacza to, że informacje z tych plików zostały również już wcześniej na sztywno wkodowane do exec'a - przez to nie musimy o tym pamiętać a środowisko programistyczne poprzez ten myk zapewnia nam zawsze minimum funkcjonalności programu umozliwiając nam jego uruchomienie lub zamknięcie.
Tylko load time umożliwi nam uruchomienie programu, gdybyśmy chcieli skorzystać z tych samych funkcji przy okazji run-time byłoby to nie możliwe - zaraz przekonasz się dlaczego.
Jeszcze jedna kwestia odnośnie tego czy plik nagłówkowy biblioteki jest potrzebny czy można z niego zrezygnować - otóż nie jest on niezbędny, plik nagłówkowy jak wiemy nie robi nic więcej niż sprawdza czy deklaracja w nim siędzace są już znane (strażnik nagłówka ) oraz wkleja po prostu swoją treść do programu.
Jeśli importujesz z dll funkcję void f() to zamiast dodania dll.h możesz napisać:
zauważ że jest to dokładnie to samo co zawiera plik nagłówkowy więc o ile deklaracja się nie powtórzyła program zaakceptuje to i rozpozna funkcję z biblioteki.
Run Time
Tutaj zasada jest taka, że ręcznie ładujemy bibliotekę do przestrzeni adresowej, poszukujemy adresu funkcji i przypisujemy ją do wcześniej zadeklarowanego wskaźnika, wywołujemy funkcję poprzez wskaźnik po czym możemy zwolnić biblioteke.
Deklaracja wskaźnika, następnie zmiennej wskaźnikowej i przypisanie adresu funkcji z biblioteki dll :
Kod absolutnie przykładowy, tymczasowo jeszcze bez związku. Popatrzmy na plik exec skompilowany w taki sposób ( pamietamy, ze w run time nie dodalismy pliku biblioteki importowanej ) ? jak widać program korzysta z funkcji KeyboardProc() z biblioteki dll o nazwie maindll.dll, ale w sekcji .idata ani widu ani slychu po tej nazwie oraz po nazwie biblioteki.

Jest to oczywiste bo w run time sięgamy po te funkcje dopiero wtedy kiedy chcemy, a możemy w ogole nie więc nie chcemy obciążać dodatkowymi informacjami pliku wynikowego w sekcji importu. Czyli nie korzystamy tu z pliku biblioteki importowanej ale korzystamy z pliku nagłówkowego! Lub __declspec( dllimport ) - jak pamiętamy każda użyta nazwa musi być wcześniej znana!
Teraz już wiesz dlaczego bezsensem byłoby wywoływać ala run time funkcje z biblioteki np. kernel32.dll ? program w ogole by nie ruszył, więc nie mógłby nawet załadować tej biblioteki i w ogole jest to bez sensu.
W przypadku run time Twoimi najważniejszymi narzędziami są funkcję LoadLibrary(), GetProcAddress() oraz wskażnik na funkcję. Musisz pamiętać też, że GetProcAddress() zwraca wskaźnik amorficzny czyli taki nijaki - dlatego musisz użyć rzutowania, żeby wiadomo było jak z tego adresu korzystać.
Ps. Jeśli w przypadku runtime zabraknie przypadkiem biblioteki to nie ma tragedi ? bo mogę coś z tym zrobić jeśli LoadLibrary zwróci mi NULL. Natomiast jeśli zabraknie Ci biblioteki w przypadku kompilowania i lączenia load time to zobaczysz błąd na ekranie i nie uda Ci się uruchomić programu.
Ps2. Load time nazywany jest inaczej łączeniem statycznym!
Narazie tyle, choć ani słowa o CreateRemoteThread() czy SetWindowsHookEx() - muszę odszukać kod z programem, który parsuje tablice IAT i podmienia funkcję poprzez zdalny wątek i wtedy napiszę coś więcej.

Całość polega na tym, że mamy jeden uruchomiony proces - innym procesem 'wbijam' się w przestrzeń adresową procesu pierwszego i przy pomocy biblioteki DLL procesu drugiego wykonuję funkcję w przestrzenii procesu pierwszego. Pierwszy proces wyświetla zwykłe "Hello world" - drugi całą resztę. Przy pomocy tej techniki łatwo zdemolować inną aplikację. Programista będzie się zastanawiał co nie działa w jego programie, podczas gdy źródło problemu leży zupełnie gdzie indziej.
 Today I'd like to present how to combine share permissions and NTFS when granting network access to a particular resource for a particular user (or group). I've made a graphic that tells more than a...
Today I'd like to present how to combine share permissions and NTFS when granting network access to a particular resource for a particular user (or group). I've made a graphic that tells more than a...